数据库索引mysql的结构和性能
数据库索引-MySQL索引结构和性能
数据库索引可加快数据检索操作,但是我们也为这些好处付出了代价。 在本文中,我们将关注MySQL索引背后的结构。通过使用大型数据集来测试数据库性能,我会测试同一数据库的两个版本:一个具有索引,另一个没有。 这是我们关于数据库索引的系列文章的第二篇。第一篇请单击此处。
索引使用什么数据结构?
> MySQL支持几种不同的索引类型。最重要的是BTREE树和HASH。这些类型也是其他DBMS中最常见的类型。
在我们开始描述索引类型之前,让我们快速回顾一下最常见树的节点类型:
- 根节点 - 树结构中的最顶层节点
- 子节点 - 另一个节点(父节点)指向的节点
- 父节点 - 指向其他节点(子节点)的节点
- 叶节点 - 没有子节点的节点(位于树结构的底部)
- 内部节点 - 所有“非叶子”节点,包括根节点
- 外部节点 - 叶节点的另一个名称
二叉搜索树(BST)
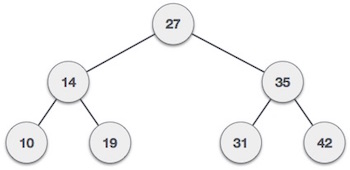
上图是一个二叉搜索树(BST)结构,这些结构不是数据库索引使用的数据结构,但数据库使用的树结构(B-Tree和B + Tree)和BST相似的。
BST是二叉树,其中节点被排序。在上图中,我们看到节点X左侧的值小于X,节点X右侧的值更大。这就是任何BST的组织方式。
当我们在BST中搜索值时,我们从根节点开始,并将搜索到的值与根节点的值进行比较。如果搜索的值低于根值,我们将转到左子树。相反,则去右边的子树查找。如果我们找到了对应的值,完成查找 。如果到达叶节点而没有找到我们的值,就能知道所查找的值不在这个BST的树中。
向BST添加新值就像搜索值一样。 (一旦我们为我们的值找到合适的位置,当然,过程会发生变化。)例如,如果我们要添加值“30”,我们会将其添加为节点“31”的左子节点(30)大于27,所以我们向右走; 30小于35,所以我们向左走; 30小于31,所以我们再向左走。)
当想要从BST中删除一个值时,情况就更复杂了。在某些情况下,甚至可能需要重新排列树。有三种可能的情况:
- 删除没有子节点的节点 - 我们只需从BST中删除该节点。在我们的例子中,这些是节点“10”,“19”,“31”和“42”。
- 删除具有一个子节点的节点 - 我们将用子节点替换已删除的节点。如果节点“31”在左子树中具有“30”作为子节点并且我们将其删除,则我们将简单地将“31”替换为“30”。
- 删除具有两个子节点的节点 - 这是最复杂的情况。在这种情况下,我们将找到已删除节点的右子树中的最小元素,并将其放在已删除节点的位置。因此,如果我们删除节点“27”,我们将在右侧子树中查找最小值,即“31”。我们将节点“27”替换为节点“31”。
B-Tree
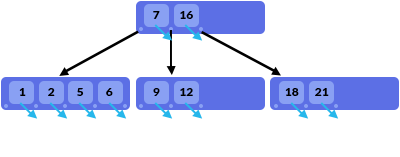
B-Tree是大多数MySQL存储引擎的基本索引结构。 B树中的每个节点具有d至2d个值,并且每个节点中的值都已排序,每个节点具有0到2d + 1个子节点。每个子节点都附加在值之前,之后或之间。 (在上图中,值“9”和“12”介于值“7”和“16”之间。) B-Tree中的值以与二叉搜索树中的值类似的方式排序。值“X”左侧的子节点的值小于X;值“X”右侧的子节点的值大于X(参见图片)。
与BST相比,B树是平衡树:树的所有分支具有相同的长度。
在B树中搜索值也类似于在BST中搜索。首先,我们检查根节点中是否存在该值。如果不存在,则选择适当的子节点,并在该节点中查找值。
在B树中添加和删除值通常不会创建新节点:每个节点中的值的数量可以变化。当然,这意味着我们将有一些空的空间,因此B树将需要比更密集的树更多的磁盘空间。
添加值必须保持值的顺序和树的平衡。首先,我们将找到应添加值的叶节点。如果叶节点中有足够的空间,我们只需添加该值;结构和树深度不会改变。
在我们的示例中,添加值“22”将非常简单。我们只需将其添加到第三个叶节点。如果我们想要添加值“4”,我们将分割第一个叶节点。这总是在溢出的情况下发生。值“1”和“2”将形成一个新的叶节点(左侧节点);值“4”将是中间节点(并插入到父节点中),而值“5”和“6”将形成另一个新的叶节点(右侧节点)。
如果在那里发生溢出,我们将以相同的方式拆分父节点。在极端情况下,我们必须拆分根节点,树深度会增加。
当我们想要从B树中删除一个值时,我们将找到该值并将其删除。如果该删除导致下溢(存储在节点中的值的数量太少),我们将必须将节点合并在一起。这与我们添加值时发生的情况完全相反。我们将该节点与包含最多值的邻居节点合并。如果新合并的节点包含太多的值(溢出),我们将它分成左,中,右,并重新排列树结构。
当在数据库索引中使用B-Tree时,每个节点都保存索引值和指向它来自的行的指针。例如,如果索引位于列id上,则树将同时保存值“7”和指向id = 7的行的指针。当我们搜索id = 7的行时,我们可以在B-Tree中快速找到值7,然后按照指针获取实际的行。
重要一点是,在B树结构中,每个节点都包含键值,指向值的指针以及指向子节点的指针,子节点的值小于父节点中的值。当然,叶节点不指向任何子节点。 使用B-Tree索引,我们可以使用相等运算符(=或<=>),将产生范围(>,<,> =,<=,BETWEEN)和LIKE运算符的运算符。 我们也可以在多个列上创建索引。如果我们在(first_name,last_name)对上创建索引,我们可以使用任一术语进行搜索,但是当我们仅使用其中一个属性时,索引也会起作用。 最后,值得注意的是,当最常访问的数据更接近根节点时,B树将表现得更好。
B+Tree
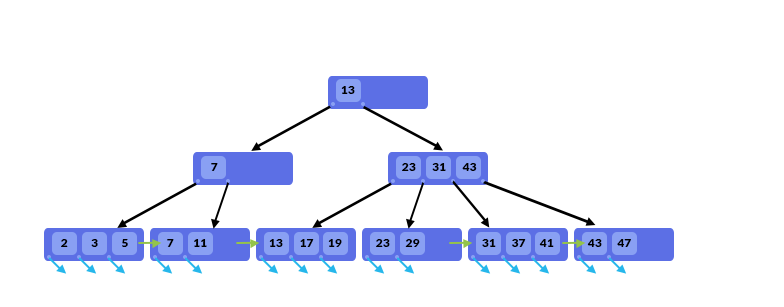
B+Tree结构类似于B-Tree结构。区别是:
- 内部节点只存储值;它们不存储指向实际行的指针。叶节点存储值和行指针。这减少了内部节点的大小,允许在同一内存页面上存储更多节点。反过来,这增加了分支因子。随着分支因子的增长,树的高度会降低,从而导致更少的磁盘I/O操作。
- B+Tree中的叶节点是链接的,因此我们只需一次传递就可以进行全扫描。当我们需要查找给定范围内的所有数据时,这非常有用。因为行指针存储在内部节点和叶节点中,这在B树中是不可能的。
- 在B+Tree结构中执行删除操作比在B树中更容易。这是因为我们不需要从内部节点中删除值。在B+Tree结构中,我们将重复相同的值;在B树结构中,每个值都是唯一的。在B+Tree中,我们将在叶节点中存储一个值和一个数据指针,但该值也可以存储在内部节点中(用于指向子节点)。
- B-Tree的优点是我们可以很快找到靠近根的值,而在B+Tree中,我们需要一直向下查看叶节点的任何值。
InnoDB存储引擎使用B+Tree结构来存储索引。
Hash索引
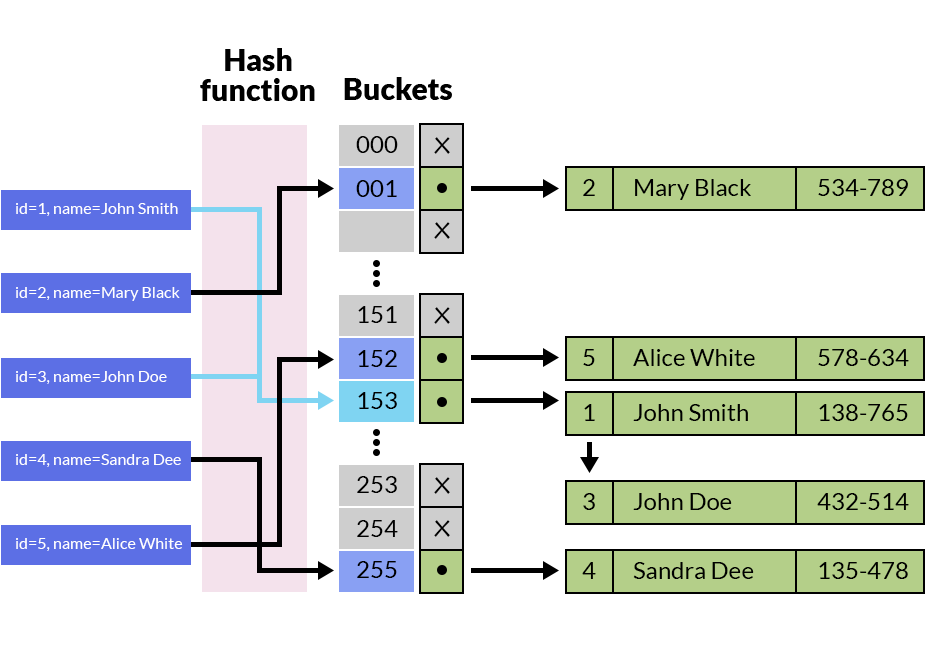
散列索引与散列技术直接相关。如上图,在左侧,我们看到用于查找数据的一组键值。在这种情况下,它们是数值。哈希函数用于计算存储实际数据桶的地址。这将为我们提供与每个键值相关的记录的位置。
值基于散列函数的值存储在存储桶中。当我们想要搜索一个值时,我们将使用哈希函数来计算可以存储数据的地址。我们将在桶中查找数据。如果我们找到它,我们就完成了。如果我们没有找到我们的价值,那就意味着它不在索引中。
添加新值的工作方式类似:我们将使用哈希函数来计算我们存储数据的地址。如果该地址已被占用,我们将添加新桶并重新计算哈希函数。再一次,我们将使用整个键作为我们函数的输入。结果是我们可以找到所需数据的实际地址(在磁盘存储器中)。
更新或删除值包括首先搜索值,然后对该内存地址应用所需的操作。
在测试相等性(=或<=>)时,哈希索引非常快。这是因为我们使用的是整个密钥而不仅仅是其中的部分。当我们想要查找范围,使用<或>运算符或加速子句的ORDER BY部分时,Hash索引无法帮助我们。
如果我们要指定索引结构,我们需要在CREATE INDEX语句中添加USING BTREE或USING HASH。
性能测试
数据库架构及预期结果
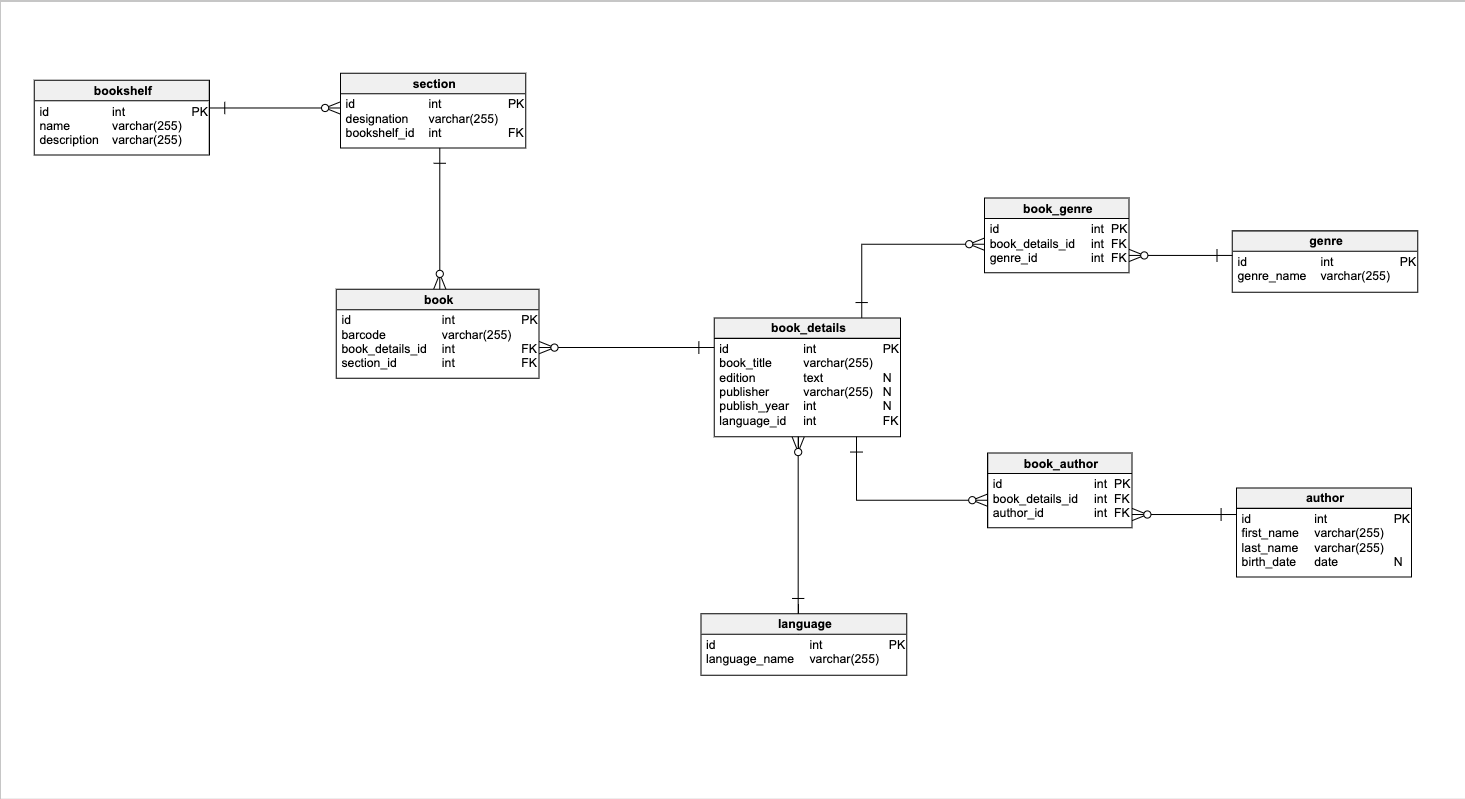
我们将测试两个相同数据库的性能,一个使用索引,另一个不使用索引。为简单起见,我们将这些称为索引和未索引的数据库,即使两个数据库的主键都有索引。两个数据库的结构在上面的模型中给出,并在本系列的第1部分中详述。
在测试数据库中,我在book,book_details,book_genre和book_author表中添加了1,000,000条记录。 在第一篇文章中,我们使用以下语句创建了三个索引:
CREATE INDEX book_details_idx_1 ON book_details (book_title);
CREATE INDEX author_idx_1 ON author (first_name,last_name);
CREATE INDEX author_idx_2 ON author (last_name,first_name);
要从第二个数据库中删除这些索引,我们使用以下语句:
DROP INDEX book_details_idx_1 ON book_details;
DROP INDEX author_idx_1 ON author;
DROP INDEX author_idx_2 ON author;
预期结果:
使用索引的数据库也应该使用更多的磁盘空间。请记住,索引是索引属性和指向记录的指针的结构和存储副本。期望用于查找和排序数据的查询(SELECT,ORDER BY)在索引数据库上的执行速度比未索引的数据库快。但是,当我们使用INSERT,DELETE和UPDATE查询时,未索引的数据库应该会更好。
数据库占用大小
每个MySQL服务器实例都存储每个数据库的所有相关数据在information_schema数据库中。所以我们可以查询到有关server, tables, columns, views, triggers, 等所有相关的数据。
查询information_schema数据库以查找两个示例数据库的大小:
SELECT
ROUND(SUM(information_schema.tables.data_length + information_schema.tables.index_length) / (1024 * 1024), 2) AS "MB"
FROM information_schema.tables
WHERE information_schema.tables.table_schema = "indexes_performance";
正如所料,索引数据库的大小为315 MB,而未索引的数据库为289 MB。这可能看起来不是很大差异,但它大约是10%,我们只使用了三个索引。
使用以下查询更详细地查看这两个数据库:
SELECT
a.table_name,
a.MB AS "table size; data + index (MB) / INDEX",
a.index_MB AS "index size (MB) / INDEX",
b.MB AS "table size; data + index (MB) / NO INDEX",
b.index_MB AS "index size (MB) / NO INDEX"
FROM
(
SELECT
information_schema.tables.table_name AS table_name,
ROUND(SUM(information_schema.tables.data_length + information_schema.tables.index_length) / (1024 * 1024), 2) AS "MB",
ROUND(SUM(information_schema.tables.index_length) / (1024 * 1024), 2) AS "index_MB"
FROM information_schema.tables
WHERE information_schema.tables.table_schema = "indexes_performance"
GROUP BY information_schema.tables.table_name
) AS a
LEFT JOIN
(
SELECT
information_schema.tables.table_name AS table_name,
ROUND(SUM(information_schema.tables.data_length + information_schema.tables.index_length) / (1024 * 1024), 2) AS "MB",
ROUND(SUM(information_schema.tables.index_length) / (1024 * 1024), 2) AS "index_MB"
FROM information_schema.tables
WHERE information_schema.tables.table_schema = "indexes_performance_no"
GROUP BY information_schema.tables.table_name
) AS b
ON a.table_name = b.table_name
结果如下:
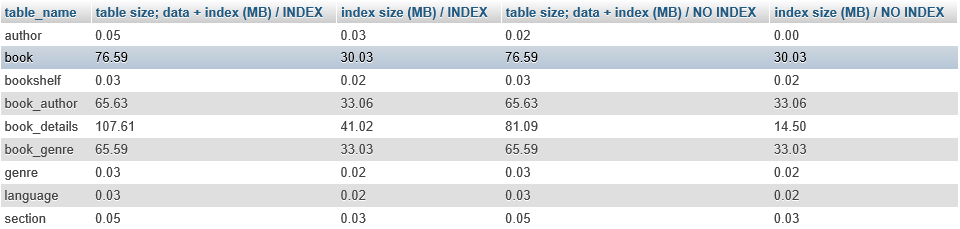
第一列是表名,对于两个数据库都是相同的。第二列和第三列属于索引数据库,而第四列和第五列属于未编制索引的数据库。第二列和第四列是数据大小和索引大小的总和,而第三列和第五列是索引大小。
正如所料,index_details和author表在索引数据库中更大。我们还可以看到,即使在没有添加自定义索引的数据库中,也为索引保留了大约110 MB。这是在主键属性上创建的索引的大小。数据库大小的几乎所有差异都来自book_details表上添加的自定义索引。
查询速度
我们将使用相同的数据库,但这次我们将测量执行三个SELECT查询所需的时间,以及一个包含许多数据更改的存储过程。
第一个查询非常简单:
SET @start_time = NOW();
SELECT book_details.book_title, COUNT(*) AS result
FROM book_details
GROUP BY book_details.book_title;
SET @end_time = NOW();
SELECT TIMEDIFF(@end_time, @start_time) AS difference;
要返回执行查询所需的时间,请在查询之前和之后立即设置@start_time和@end_time。他们的不同将告诉我们这项行动需要多长时间。 索引数据库返回的结果比未索引的数据库快17倍。未索引的版本被迫对信息进行顺序搜索,以便考虑时间差别。
提示:MySQL支持以下语句:
- DESCRIBE - 通常用于描述表结构
- EXPLAIN和EXPLAIN EXTENDED - 用于描述查询执行计划
- SHOW WARNINGS - 用于在执行观察语句后显示有关条件(错误,警告等)的信息 DESCRIBE,EXPLAIN和EXPLAIN EXTENDED放在查询的前面。显示警告应该放在它之后。
我们将使用的第二个查询更复杂,我们可以预期两个数据库的执行时间都会增加:
SET @start_time = NOW();
SELECT author.first_name, author.last_name, COUNT(*)
FROM book_details, book_author, author
WHERE book_details.id = book_author.book_details_id
AND book_author.author_id = author.id
GROUP BY author.first_name, author.last_name
ORDER BY author.first_name, author.last_name;
SET @end_time = NOW();
SELECT TIMEDIFF(@end_time, @start_time) AS difference;
在这种情况下,索引数据库给我们的结果比未索引的数据库快两倍。
我们稍微修改第二个SELECT查询,添加一个选择条件:
SET @start_time = NOW();
SELECT author.first_name, author.last_name, COUNT(*)
FROM book_details, book_author, author
WHERE author.first_name = "Ernest"
AND book_details.id = book_author.book_details_id
AND book_author.author_id = author.id
GROUP BY author.first_name, author.last_name
ORDER BY author.first_name, author.last_name;
SET @end_time = NOW();
SELECT TIMEDIFF(@end_time, @start_time) AS difference;
索引数据库再次返回其结果的速度比未编制索引的数据库快两倍。这是因为我使用了索引列; GROUP BY和ORDER BY子句在可用时使用索引。当然,该索引必须包含与GROUP BY和ORDER BY子句中使用的相同顺序的相同列。
所有三个测试用例的结果都符合预期。当我们使用SELECT查询时以及需要ORDER返回值时,索引会显着提高性能。
最后
记住这样一个事实:当我们添加,更改或删除记录时,索引数据库需要时间来修改索引结构。
索引是非常强大的数据库结构。处理较小的数据集时,您可能不需要它们。但随着事情变得复杂,索引在整体表现中起着至关重要的作用。我们提出了三种常用的索引结构,我们已经考虑了它们的优缺点。在测试期间,我们已经证明索引在检索和更改数据时可以带来更好的性能。