数据库索引基本知识
数据库索引–基本知识
有许多因素会影响数据库性能。最明显的是数据量:您拥有的数据越多,数据库的速度就越慢。虽然有很多方法可以解决性能问题,但主要的解决方案是正确索引数据库。
为什么需要数据库索引?
要回答这个问题,我们将讲述一个故事。让我们假设我们管理一个图书馆,我们有一个数据库来存储有关我们图书的信息。对于每本书,我们存储条形码,标题,作者,流派,出版商和出版年份。我们可以将所有这些保存在一个大文件中,每行代表一本书。在这种情况下,根据记录的添加时间,书籍的顺序将按时间顺序排列。 如果我们想找一本书,我们需要扫描列表中的每一条记录。从文件的开头开始,我们将测试每条记录的搜索条件。在我们找到第一个匹配值后,搜索将被终止 - 这可能是最后一个记录!从技术上讲,这种方法有效;但随着我们的文件变大,对性能的影响将变得更加明显。在某些时候,我们的系统将变得无法使用。 此方案可以轻松应用于数据库,还有一些其他因素。例如,每个数据库记录应至少有一个唯一键。该密钥可能包含一些实际数据,但在大多数情况下,它只是一个自动分配的数值。要在我们的数据库中查找任何给定记录,我们必须使用:
- 主键值,如果我们知道的话。请记住,主键不是真实数据,所以我们很少有机会知道这个值。
- 真实的值,如书的标题或作者。
即使有了这些信息,对大量数据进行排序也很耗时。只需要查看您所在城市主图书馆中每本书的清单,即可找到一个标题!幸运的是,有一种更有效的方法可以完成任务。 为了加快速度,可以依赖于数据库索引。
什么是数据库索引?
数据库索引是一种专用数据结构,允许我们快速定位信息。它的组织方式类似于二叉树结构,左侧值较小,右侧值较大。索引可以比较树状结构中的行值,以更快地定位所需数据,而不是强制扫描整个表。
当我们在一个或多个列上创建索引时,我们将它们的值存储在新结构中,还存储指行的指针。这行为会重新组织并排序信息,但不会改变信息本身。可以将数据库索引视为书后面的索引。虽然它存储了一些实际信息,但它还包含指针,指针指向可以找到更多详细信息的位置。
按照我们的搜索条件对数据进行排序后,查找所需的记录会变得更加简单。想象一下按字母顺序排序的旧电话簿。知道某人的姓氏,名字和地址意味着您可以很快找到他们的电话号码。但是如果你只知道别人的地址和名字怎么办?没有姓氏,找到电话号码将非常困难。您可以使用反向电话簿做得更好,该目录列出了基于地址的电话号码。
在数据库中,更改搜索条件通常意味着为属性组合创建新索引。如前所述,添加这些索引需要额外的磁盘空间。添加,删除或更新值时,还会对索引进行更改。
为什么索引很重要 - 背后的数学原理
在大多数情况下,我们可以使用索引比通过数据库顺序搜索更快地找到数据。例外情况是我们的数据库中只有几条记录。如果我们在公式中表达这个,t = time,那么tusing_index < tsequential search。我们可以计算这些值,计算结果是算法复杂度的公式。
算法复杂度决定了执行操作所需的时间。由于硬件配置不同,我们将使用数据集中的数据量作为参数,其中n =数据库中的记录数。所以,如果我们的图书馆有1000000本书,那么n = 1000000。
如果我们想找到哈克贝利·费恩历险记的记录,我们必须查看每个单独的书名,直到找到合适的书名。如果n = 1000000,这意味着平均会有50万本书!此顺序过程称为全表扫描,算法复杂度(n / 2)与数据集的大小直接相关。我们将使用O(n)指向它。注意:“O”用于描述算法中最重要的术语。例如,如果我们计算算法具有2n3 + 4n + 21操作,则该算法的大O表示法是O(n3)。
另一方面,如果我们在title属性上使用索引,我们可以更快地找到我们的记录。如果这些书籍已按字母顺序按标题排列,我们只需查看中间的书籍(第500000条记录)。如果我们的期望值出现在此记录之前,我们将在左侧数据子集中搜索它;否则,我们会查看正确的子集。通过继续将我们的列表分成两半,我们将找到我们想要的记录。我们需要重复这个过程的最多次数是20次(2 ^ 20 = 1048576)。这种算法的复杂性表示为O(log(n))。
显然,索引方法获得了更好的结果。使用它有一个先决条件,那就是在title属性上有一个索引。这将导致更快的搜索操作,但是在添加和删除数据时,我们将丢失一些磁盘空间并且性能会降低。
示例数据库模型
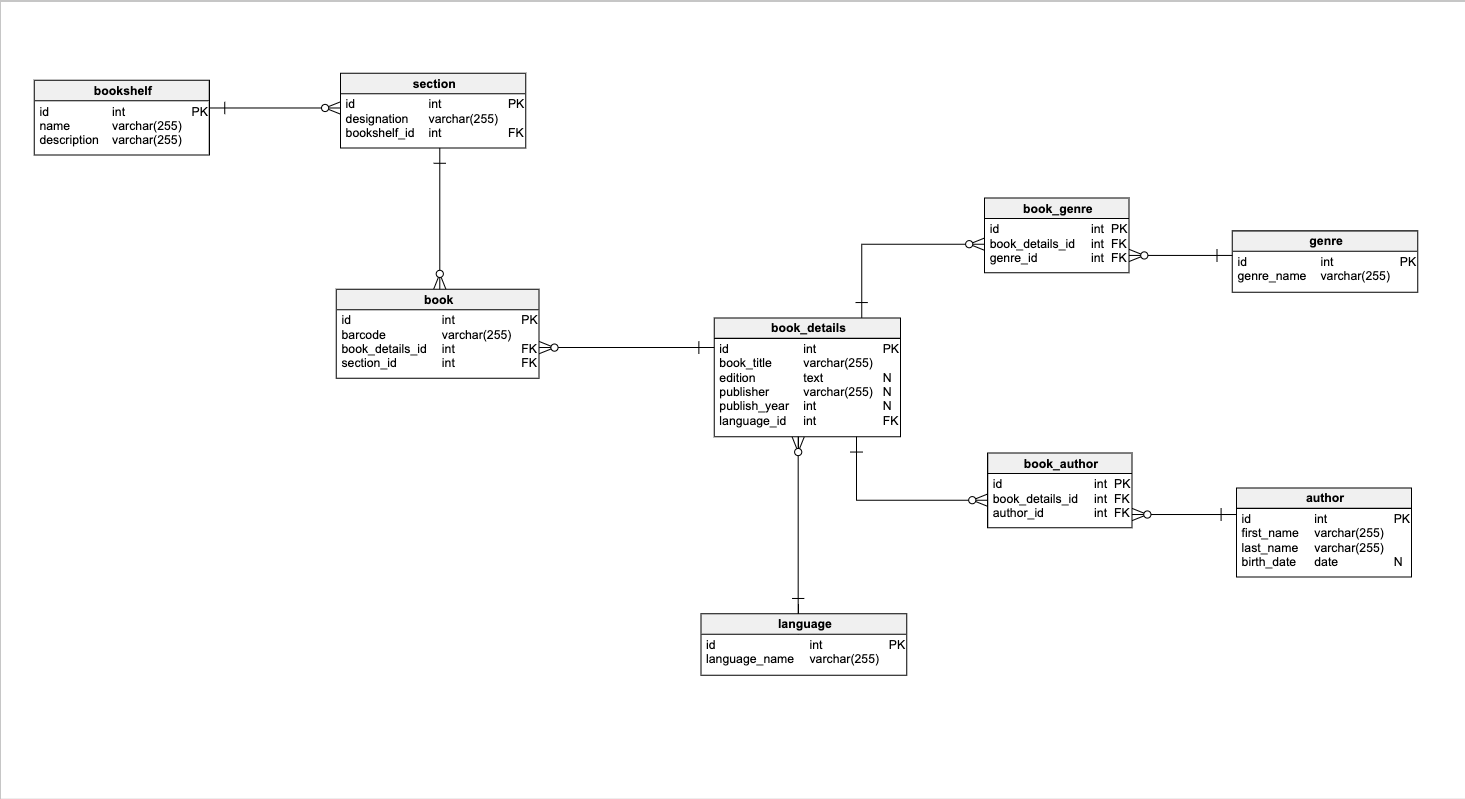
我们将使用此模型来解释本文和即将发表的文章中的索引。它旨在存储有关我们图书馆书籍的所有相关数据。
我不会进入模型细节,最重要的是要知道一些表格:
- 是字典,我们不期望经常改变。
- 包含大量数据(book,book_details,book_genre,book_author)。
如何创建索引
添加新索引需要更多磁盘空间。如果我们尝试索引每个属性和所有可能的组合,我们最终可能会遇到比我们最初的更差的性能。因此,在考虑新索引时,请记住:
- 仅在我们期望大量数据的表中添加索引。在我们的模型中,可能是book_details表。
- 只为我们希望经常搜索的属性添加索引;例如,假设人们将搜索书名是合乎逻辑的,因此book_title属性将具有索引。
- 如果UNIQUE无法帮助我们,请在字段中添加索引。例如,在book_details中,几本书完全有可能具有相同的名称。
- 如果我们为索引使用多个字段,我们必须正确地对它们进行排序。
我们可以使用以下SQL语句轻松地在book_title属性上创建索引:
CREATE INDEX book_details_idx_1 ON book_details (book_title);
以下代码,用于创建表:
-- Table: book_details
CREATE TABLE book_details (
id int NOT NULL AUTO_INCREMENT,
book_title varchar(255) NOT NULL,
edition text NULL,
publisher varchar(255) NULL,
publish_year int NULL,
language_id int NOT NULL,
CONSTRAINT book_details_pk PRIMARY KEY (id)
)
COMMENT 'list of all book titles';
CREATE INDEX book_details_idx_1 ON book_details (book_title);
-- End of file.
使用相同的逻辑,我们将在author表上创建另外两个索引。第一个索引使用first_name列,然后使用last_name列。第二个索引反转此顺序,首先使用last_name列,然后使用first_name列。它们看起来可能相同,但索引中列的顺序至关重要;创建索引,以便索引中最左边的属性是您首先使用的属性。
为什么同一属性上有两个索引?人们可能会以几种不同的方式搜索作者。第一个索引author_idx_1允许我们仅使用first_name - last_name对或first_name属性查找记录。但它不适用于last_name– first_name对甚至last_name属性。第二个索引author_idx_2将执行此操作。因此,无论作者的姓名如何输入搜索,都会返回有意义的结果。
我们表的CREATE TABLE语句现在如下所示:
-- tables
-- Table: author
CREATE TABLE author (
id int NOT NULL AUTO_INCREMENT,
first_name varchar(255) NOT NULL,
last_name varchar(255) NOT NULL,
birth_date date NULL COMMENT 'it is here just to distinguish authors with same first and last name (if any)',
CONSTRAINT author_pk PRIMARY KEY (id)
)
COMMENT 'authors list';
CREATE INDEX author_idx_1 ON author (first_name,last_name);
CREATE INDEX author_idx_2 ON author (last_name,first_name);
-- End of file.
使用数据库索引需要注意的事情
如果一个表有一个或多个索引,它肯定会减慢INSERT操作。这是因为当记录添加到表中时,它必须在正确的位置。因此,需要调整索引,这需要时间。
如果我们期望具有索引的表发生重大更改,我们可以先删除索引,插入新记录,然后重新创建索引。根据具体情况,这可能是更快的解决方案。在我们的模型中,如果我们要添加大量新书,那么删除索引是有意义的。假设我们准备一份新书及其相关数据列表并在工作时间后运行脚本是合理的。
自动索引的一些情况
- 将自动为主键创建索引。在我们所有的表中,主键都被称为id。它是int类型,autoincrement设置为yes。
- 在MySQL InnoDB引擎中,还会自动为外键创建索引。
- 如果将属性定义为UNIQUE,则还会自动在其上创建索引,就像对主键一样。
在以上情况下,都会在键值上创建索引,从而加快搜索操作(当使用id作为搜索参数时)。这有助于我们知道id并且我们想要检索,更新或删除该记录的值。 索引非常强大。它们允许我们更快地执行搜索和排序操作。但是这个速度需要付出代价:创建索引需要磁盘空间并且可能会降低其他操作的速度。