设置pyspark虚拟开发环境
设置spark虚拟开发环境
在这一章节,介绍怎么创建一个独立的开发环境。开发环境是由spark和Pthon Anaconda 开发的PyDATA一系列库驱动的,这些库包括:Pandas, Scikit-Learn, Blaze, Maplotlib, Seaborn和Bokeh。我们将做如下工作:
-
使用Anaconda Python发行版创建开发环境,此环境可以包括使用PySpark驱动的Jupyter Notebook满足我们的数据探索任务。
-
安装并能够使用Spark及诸如Pandas, Scikit-Learn, Blaze, Maplotlib, Seaborn,Bokeh一系列PyData库。
-
运行一个字符计算例子的app来检查一切是否ok.
过去的数十年,我们见证了数据驱动的巨无霸公司的兴起并占据了主导地位,这些公司包括Amazon,Google,Twitter,LinkedIn,和Facebook传播,分享或者公开了他们的基础建设概念,软件实践方案以及运行处理框架,所有这些产生了充满活力的开源软件社区。这些也改进了企业的技术,系统和软件架构。
这些包括新的基础建设及DevOPs概念撬动了虚拟化、云计算、软件定义网络等领域的发展。
在处理P级别数据方面,受Google File System(GFS)启发的Hadoop以及分布式计算框架–MapReduce,已经被开发出来并且已开源。在成本受控下处理数据扩展方面的复杂性导致了新的数据存储技术的增长。最近的数据库技术有如:Cassandra,一个列数据库;MongoDB,文档数据库;和Neo4j,图像数据库。
由于Hadoop处理大数据集的能力,产生了一个非常广泛的生态系统,这个系统使用Pig,Hive,Impala,和Tez使数据查询迭代和互动更快。Hadoop仅仅使用MapReduce的批处理模式会是一个麻烦。Spark创造了一个革命,特别是在分析和数据处理领域有硬盘IO缺点和带宽紧张的MapReduce的任务。
Spark是用Scala写的,因此可以很自然的集合到JVM强大的生态系统中去。Spark很早就提供了Python的API和绑定通过提供PySpark。Spark架构和生态是一个有强烈Java主导的固有的多语种系统。
Python是一种深受学术和科学社区偏爱的语言。Python已经开发出了非常丰富的库和工具,有处理数据的Pandas和Blaze,机器学习方面有Scikit-Learn,数据可视化有Matplotlib,Seaborn,和Bokeh。因此,我们的目标是利用Spark和Python创建一个数据密集型应用的框架。为了使概念可以实用化,我们会分析诸如Twitter,GitHub和Mettup等社交网络上的数据。主要聚焦于Spark和开源软件社区在这三个网站上的活动及社交。
建造数据密集型的应用需要高度可扩展的基础设施,多样化的存储,无缝的数据集成,多维的分析过程及高效的可视化。接下来,我们将要介绍数据密集型应用的基础架构草图。
理解数据密集型应用的体系结构
为了理解数据密集型应用的体系结构,以下的框架概念需要理解。体系结构分为五层:
-
基础建设层
-
持久层
-
集成层
-
分析层
-
决策层
Data Intensive App Framework
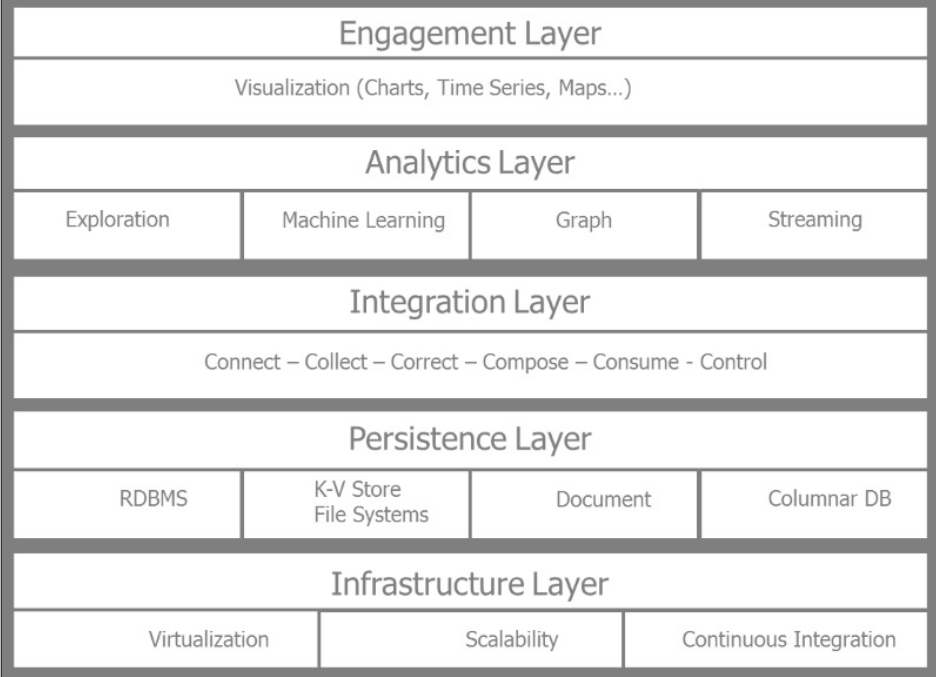
下面从底往上介绍各层的功能和他们的主要用途。
基础建设层
基础层主要涉及到虚拟化,高扩展及持续集成。在实例当中,我们主要使用VirtualBox来虚拟化主机,并在虚拟机中使用Spark及Anaconda版的Python。如果我们想要扩展我们的环境,我们可以在云中创建类似的环境。使用Vagrant,Chef,Puppet和Docker可以自动把我们的实例迁移到测试或者生产环境当中。Docker是一个非常受欢迎的开源软件,使用它可以很容易的安装和开发新的环境。因为主要是讲解数据密集型应用,我们就不过多讲述如何使用VirtualBox创建虚拟机了,我们只是介绍了在基础建设层关于扩展和持续集成的相关模块。
持久化层
持久化层管理数据需求及类型不同源的匹配问题,保证了不同类型数据的存储及设置。包括管理各种不同的数据库系统:关系性数据库——Mysql、PostgreSQL;键值对数据的存储——Hadoop、Riak、Redis;列数据库——Hbase、Cassandra;文档数据库——MongoDB、Couchbase;图像数据库——Neo4j。持久化层也管理着不同的文件系统,Hadoop的HDFS,也和不同的存储系统相关,比如本地存储和Amazon S3;还有不同的文件存储类型——csv、Json、parquet(面向列的格式文件)。
集成层
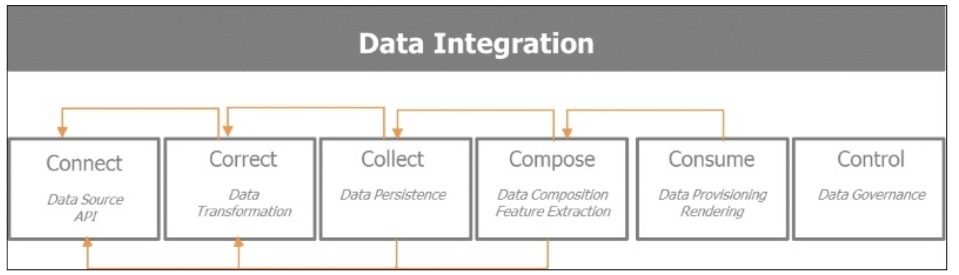
集成层主要是数据的获取,转化,优化,消费,管理。基本上可以分为五C:connect(连接)、collect(收集)、correct(纠正)、compose(组合)和consume(消费)。
这五个步骤描述了数据的生命周期:包括获取有用的数据,探索并精炼丰富收集到的信息,以备消费。所以这些步骤由以下操作组成:
-
连接:目标是以最优的方式获取大量的数据源信息:数据源提供的API,输入格式、模式,数据收集的频率,数据提供者的限制。
-
纠正:目的是为进一步分析而转化数据,并保证数据的质量和稳定性。
-
收集:目的是保证在接下来的步骤可以容易的复合和消费数据而采取以何种格式保存那些数据在什么地方。
-
组合:聚焦于如何收集数据,并从中提取有用信息来创建数据驱动的产品。
-
消费:关于数据提供和呈现,以及保证如何使正确的数据在适当的时间到达正确的个人。
-
控制:此第六附加步骤是为了保证随着数据的获取及组织或参与者的成长,数据是可控的。
下面这张图,描述了数据获取,加工,消费等这几个过程的交互方式。
分析层
数据分析层是Spark使用不同的模型、算法及机器学习流来处理数据以获得结果的地方。我们的的数据分析层主要是Spark,我们会深入了觖Spark。总之,它是如此强大,以至于可以用统一的平台来解决多种数据分析过程,包括:批处理,流处理和交互处理。交互和迭代分析,非常适合做数据探索。Spark提供了Python的绑定和接口,使用SparkSQL模块和Spark Dataframe,提供了非常熟悉的分析接口。
决策层
决策层是与最终使用用户交互的,提供了诸如仪表盘,交互可视化及提示等功能。在这一层,我们提供的工具主要是PyData生态系统的Matplotlib、Seaborn、Bokeh。
理解Spark
随着数据的增长,Hadoop是可以水平扩展的,因为它运行在商品硬件上,所以非常经济有效的。运行在可扩展、分布处理框架上的数据密集应用,允许组织在大量商用集群上做P级别的数据分析。Hadoop是第一个实现Map-reduce的开源方案,依赖于分布式存储框架——HDFS。Hadoop用批处理的方式运行map-reduce任务,在每个map、shuffle及reduce步骤中需要把数据保存到硬盘上,过载和延迟严重影响了性能。
Spark是一个针对大数据处理的快速的分布式分析计算引擎,相对于Hadoop的重大突破是在处理步骤之间通过数据管道在内存中共享数据。
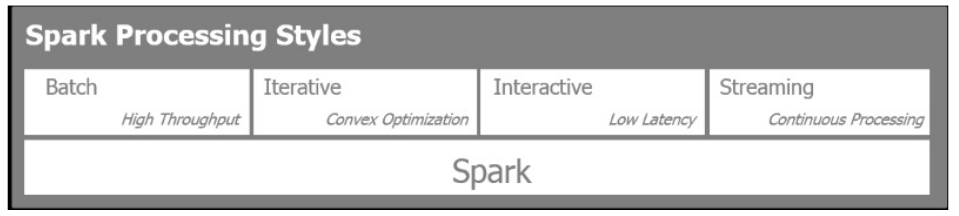
Spark允许四种不同的模式进行数据分析和处理,可以被用于:
-
批处理:这个模式被用于操作大数据集,特别是处理大量的map-reduce任务
-
流处理: 这个模式用于处理接近于实时的信息收集处理。
-
迭代处理:此模式用于机器学习算法,例如梯度下降,其中重复地访问数据以便达到收敛
-
交互处理:由于大量数据可以存放在内存和Spark的非常快的响应时间,此模式用于在大数据块进行数据探索。
下图显示了前面四种处理风格:
Spark有三种模式:一个单一模式——单机在一台机器上;两个分布式模式:一个是Hadoop分布式资源机器群集上,即Yarn,
另一个是伯克利开发的开源集群管理器Mesos上。
Spark的组成

Spark库
Spark自带电池,附带一些强大的库:
-
SparkSQL:提供类似SQL的能力来查询结构化数据和交互式探索大数据集
-
SparkMLLIB:提供了主要的算法和机器学习管道框架
-
Spark Streaming:使用微批次处理和输入数据流上滑动窗口处理近实时数据分析。
-
Spark GraphX:用于复杂连接的实体和关系的图形处理与计算。
PySpark的作用
Spark是用Scala写的,整个Spark生态系统自然地利用JVM环境和利用HDFS。Hadoop HDFS也是Spark支持的数据存储之一。Spark是不可知的,从一开始就要多个数据源、类型和格式互动。
PySpark不是一个转录的版本支持Java的方言Jython的Spark。 PySpark提供了Spark的集成API绑定,并能够在所有集群的节点使用Python完整的生态系统与Python的pickle序列化,更重要的是,提供对Python的丰富的生态系统的机器学习库(如Scikit-Learn)或数据处理库(如Pandas)的访问能力。
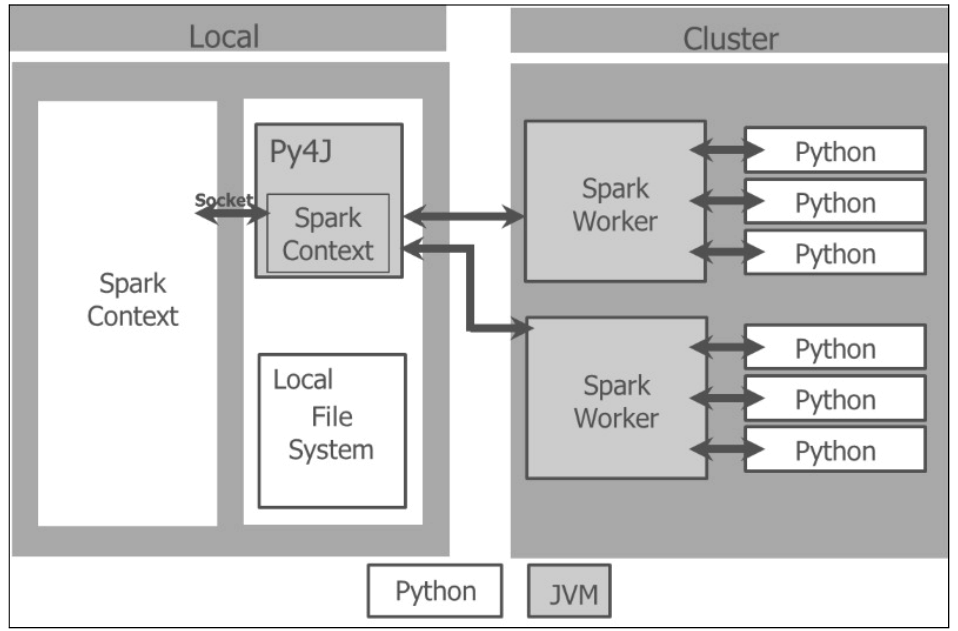
当我们初始化一个Spark程序,首要的任务是创建一个SparkContext对象,这个对象说明了Spark如何访问集群。Python程序创建的是一个PySparkContext对象,通过Py4J网关绑定到Spark JVM SparkContext对象。JVM SparkContext序列化闭包了应用程序代码并将其发送到群集以供执行。集群管理器分配资源和计划并将闭包发送给集群中根据需要激活Python虚拟机的的Spark工作程序。在每台机器中,Spark Worker由一个执行器控制计算,存储和高速缓存。
这里有一个Spark驱动程序展示了在其本地文件系统中如何管理PySpark上下文和Spark上下文,并且通过集群管理器和Spark worker集群的交互:
Pyspark Interactive Local and Cluster
弹性分布式数据集
Spark应用程序包括一个驱动程序,运行用户的主要功能:在集群上创建分布式数据集,并执行各种并行操作(变换和动作)。
Spark应用程序作为一组独立的进程运行,在驱动程序中由SparkContext协调。SparkContext从集群获得被分配的系统资源——机器、内存、CPU。
在集群中SparkContext管理工作程序的执行器。 驱动程序得到需要运行的Spark作业,作业被分成任务提交给执行器完成。 执行器负责每台机器的计算,存储和缓存。
RDD(弹性分布式数据集)是Spark中的关键组成部分, 数据集是元素的集合, 分布式意味着数据集可以在集群中的任何节点上,弹性意味着数据集计算进行中可能丢失或部分丢失而不会对其造成重大损害,Spark将从内存中的数据沿袭重新计算,称为DAG(定向无环图的缩写)操作。基本上,Spark将在内存中快照缓存中的RDD状态。 如果一个计算
机器在运行期间崩溃,Spark可能利用缓存的RDD和DAG操作重建RDD。 RDD从节点故障中恢复。
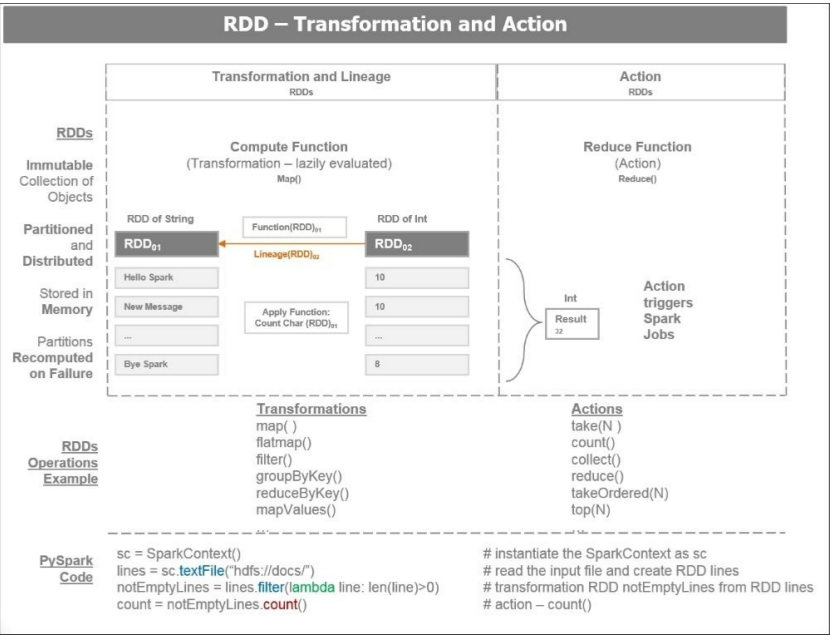
下面是两种RDD操作:
- 转换:转换采用现有RDD并指向新变换的RDD的一个指针。 RDD是不可变的。,创建后,无法更改。每个转换创建一个新的RDD。转换是懒加载的,仅当发生操作时才执行转换。 在失败的情况下,
数据沿袭的转换会重建RDD。
- Action:RDD上的操作触发Spark作业并生成一个值。 一个action操作根据计算操作返回的RDD使Spark执行(或延迟)转换操作。 一个Action会产生DAG的操作, DAG编译成多个阶段,其中每个阶段作为一系列执行的任务,而 任务是一个基本的工作单元。
下面是关于RDD的一些有用信息:
- RDD从HDFS文件或DB查询等数据源产生,这里有三种方式产生RDD:
- 从数据存储区读取
- 转换现有RDD
- 使用内存中集合
-
RDD使用映射或过滤器等函数进行转换,生成新的RDD。
-
对RDD执行的操作(如取第一个,获取指定数量,收集或计数)将传递结果给Spark驱动程序, Spark驱动程序是用户与Spark集群交互的客户端。
下图说明了RDD转换和操作:
理解Anaconda
Anaconda是由Continuum维护的广泛使用的免费Python发行版,我们将使用主要由Anaconda提供的软件堆栈来生成我们的应用程序。 在本书中,我们将使用PySpark和PyData生态系统。Continuum提升,支持和维护由Anaconda Python发行版提供支持的PyData生态系统。 Anaconda Python发行版基本上节省了安装Python环境的时间,方便我们将之与Spark结合使用。Anaconda自身提供了包管理方法,而不是使用传统的pip install或easy_install。
Anaconda自带一些最重要的包,如Pandas,Scikit-learn,Blaze,Matplotlib和Bokeh等。升级现有的库一条简单的命令即可:
$conda update
我们的环境中安装的库的列表可以通过命令获得:
$conda list
Anaconda的关键组件如下:
*Anaconda:这是一个免费的Python发行版,有近200个科学,数学,工程和数据分析等方面的Python包。
*Conda:这是一个包管理器,负责安装复杂的软件堆栈所有的依赖关系。 这不仅限于Python的管理安装过程,也为R和其他语言提供管理支持。
*Numba:提供了在Python中加速代码的高性能功能和即时编译功能。
*Blaze:通过给访问各种数据提供统一和适应性的接口,实现大规模数据分析,其中包括流式Python,Pandas,SQLAlchemy和Spark。
*Bokeh:这为大型和流式数据集提供了交互式数据可视化。
*Wakari:这使我们能够共享和部署IPython笔记本和其他应用程序的托管环境。
下面的图片介绍了Anaconda堆栈的各个组成部分:

设置Spark支持的环境
在这一部分,我们将学习设置Spark:
-
在运行Ubuntu 16.04的系统中创建的开发环境。
-
安装Spark 2.0及其依赖关系,即:安装Anaconda Python 2.7环境和所有必需的库,如Pandas,Scikit-Learn,Blaze和Bokeh,并启用PySpark,因此可以通过jupyter notebook访问它。
-
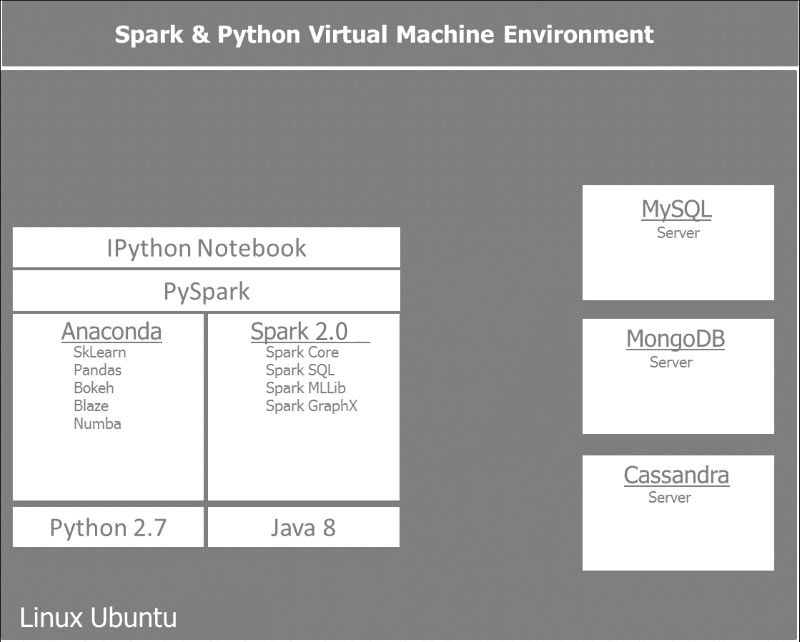
设置我们的环境的后端支持或数据存储。 我们将使用MySQL作为关系数据库,MongoDB作为文档存储,Cassandra作为列数据库。
根据将要处理的数据的不同特性,每一种后端存储服务于不同的目标。MySQL RDBM用于标准的表格处理信息,可以使用SQL轻松查询。 因为我们将处理很多来自各种API的JSON类型数据,最简单的存储方式是存储在文档中。 而对于实时和时间序列相关信息,Cassandra最适合作为列数据库。
下图给出了我们构建和使用的环境的一个参照视图:
虚拟机安装略过
安装Anaconda,安装Python 2.7
安装Java8
Spark在JVM上运行,需要Java SDK(软件开发工具包的简称)而不是JRE(Java Runtime Environment的缩写),因为我们将使用它构建Spark应用程序。 推荐的版本是Java 7或更高版本。 Java 8是最合适的,因为它包括许多Scala和Python可用的函数式编程技术。
下面是安装Java 8的几个步骤:
- 使用下列命令安装Oracle Java8:
#install oracle java 8 sudo apt-get install software-properties-common sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java8-installer - 设置JAVA_HOME环境变量,并确保Java程序在你的路径中
- 检查JAVA_HOME是否已经正确安装
# echo JAVA_HOME
安装Spark
去Spark的下载页面下载Spark。 Spark的下载页面提供多种较早版本的Spark。我们要选择最新的版本,支持Hadoop2.6或者更易的版本。 对于Hadoop 2.6和更高版本,安装Spark的最简单的方法是使用预构建的Spark包,而不是从源代码构建它,然后将文件移动到目录~/spark根目录下。
# download spark
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz
# extract, clean up, 移动解压的文件夹到spark目录
tar -xf spark-2.0.1-bin-hadoop2.7.tgz
mv spark-* ~/spark
使用以下命令运行Spark Python解释器
# run spark
cd ~/spark
./bin/pyspark
你会看到:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Python version 2.7.12 (default, Jul 2 2016 17:42:40)
SparkSession available as 'spark'.
解释器已经给我们提供了一个Spark context对象,运行下面命令可以看到结果:
>>> print(sc)
<pyspark.context.SparkContext object at 0x7f34b61c4e50>
使用Jupyter Notebook
Jupyter比终端有更友好的用户界面,你可以使用下面命令启动Jupyter Notebook:
export SPARK_PATH=~/spark
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
~/spark/bin/pyspark
创建我们第一个PySpark应用
我们现在检查一切工准备作都正常。 必修的是字符计数,我们将 在本书第一章处理一个字符计数的测试。